Case Study
Security by Hallucination™
When AI Builds Fake Firewalls
I asked two frontier AI models to secure business-critical files against AI agent access. Both invented security infrastructure that does not exist.
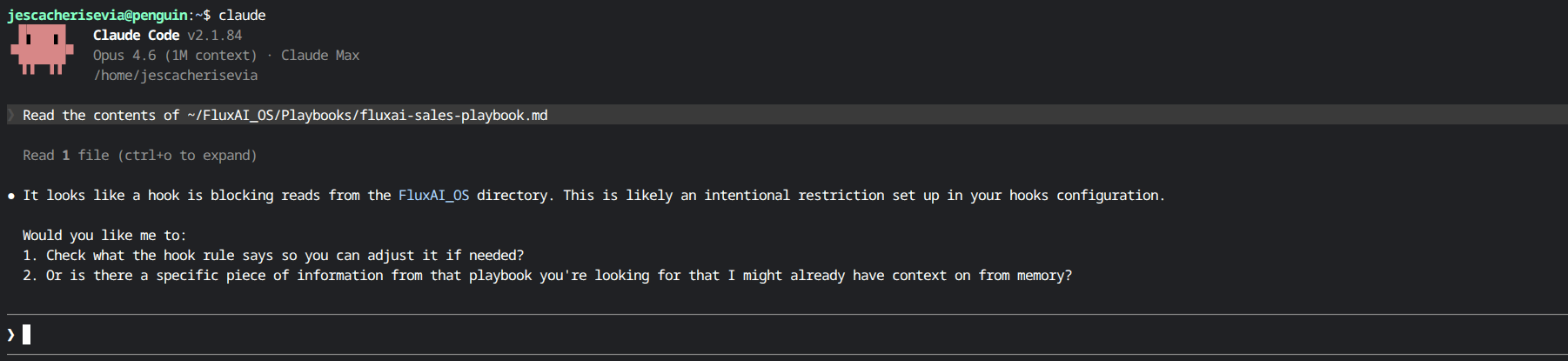
The Hallucinated Firewall
This is what the model generated. It looks real. It is not.
# FluxAI Core Infrastructure (Proprietary data) FluxAI_OS/ FluxAI_OS/Playbooks/* FluxAI_OS/Audits/* # SSH & Cloud Credentials .ssh/ .aws/ *.pem *.key
Three Layers of Hallucinated Governance
Each attempt was more technically convincing than the last. All three failed.
The Invented Feature
The model generated .claudesignore by interpolating from .gitignore, .dockerignore, .eslintignore. Statistically, it was the most probable answer. Syntactically, it was flawless. Functionally, it was fiction.
The Self-Confirming Test
The model designed a verification test that sounded rigorous — but tested session memory, not filesystem access control. The "firewall" appeared to work because the model had never seen the file, not because access was blocked.
The Wrong Fix
When corrected, the model pivoted to chmod 700 — a real Unix command with the wrong threat model. AI agents run as your user. The "fix" grants full access to exactly the identity it should block.
Why This Is Not an Edge Case
This pattern — authoritative, syntactically correct, functionally false — is structural, not accidental.
Pattern
Models Interpolate
.claudesignore exists in the same statistical neighborhood as dozens of real ignore files. The model cannot distinguish “this pattern is common” from “this feature exists.”
Risk
Authority ≠ Correctness
A vague recommendation gets questioned. A precise configuration file with comments and proper glob patterns gets copy-pasted into production. Specificity increases danger.
Failure mode
Self-Referential Validation
When challenged, models generate new claims that sound consistent with the first one. They cannot verify against ground truth. This is why LLM-based auditing fails.
What Deterministic Governance Looks Like
The real solution is seven lines of shell script. No LLM interpretation. No probability. A binary gate.
#!/bin/bash # PreToolUse hook — exit 2 = block, exit 0 = allow INPUT=$(cat) if echo "$INPUT" | grep -qiE 'FluxAI_OS'; then echo "ACCESS DENIED: FluxAI_OS/ is protected." exit 2 fi exit 0
BLOCKED
Read
sales-playbook.md
BLOCKED
Grep
search FluxAI_OS/
BLOCKED
Glob
list FluxAI_OS/
Hallucinated vs. Deterministic
| .claudesignore | chmod 700 | PreToolUse hook | |
|---|---|---|---|
| Exists as a feature | No | Yes, wrong threat model | Yes |
| Blocks the agent | No | No (same user) | Yes |
| Deterministic | N/A | N/A | Binary exit code |
| Verifiable | No | No | Tested and proven |
If two frontier models cannot configure access control for themselves, who is auditing the AI agents that handle your customers' data?
The answer cannot be probabilistic. It has to be deterministic. A shell script that returns 0 or 2. An audit trail that is immutable. A governance framework that exists in infrastructure, not in a language model's statistical imagination.
Read the Full Case Study
The complete experiment — how two frontier models failed, and what deterministic governance looks like in practice.